
Statistiques
Les statistiques sont partout. Ex : prévision météorologiques, tiercé… Les connaissances en statistiques sont utiles dans la vie de tous les jours pour comprendre le monde qui nous entoure.
La psychologie utilise des lois probabilistes, elle trouve ses exigences dans l’observation des individus, ce qui l’intéresse c’est le comportement des individus. L’observation n’est pas suffisante car pas d’explications, on peut décrire mais non expliquer. Grâce aux statistiques, on peut tenter de faire apparaître des régularités et pouvoir rédiger des théories. Les données statistiques sont fiables et stables.
Si on n’utilise pas les statistiques, on fait des études de cas.
Grâce aux statistiques, on dépasse l’observation pour aller vers l’explication.
Ex : relations statistiques entre le poids et la taille.
Les lois probabilistes sont opposées aux lois déterministes.
En statistique, on est dans un monde probabiliste. On n’est jamais certain que les évènements se déroulent comme on le pensait, et grâce aux statistiques on réduit les risques d’écart, d’incertitude. Grâce aux lois déterministes, on est sûr.
En psychologie, on ne peut pas utiliser ces lois. On utilise que des lois probabilistes car on ne voit pas la cognition, on ne voit pas de l’extérieur comment on fonctionne, on imagine d’après des comportements. De plus, on utilise des échantillons, on ne peut pas contrôler l’ensemble de la population, donc pas sûr que l’échantillon soit représentatif, là il faut faire des statistiques pour être certain.
La psychologie clinique utilise des statistiques pour comprendre les tests.
En social et en développement, on les utilise pour faire avancer les théories, grâce aux statistiques on voit si les résultats d’expérience peuvent être étendus à la population.
En statistique, il y a 2 grandes familles : descriptives et inférentielles (explicatives).
Les deux sont liées. On peut faire soit que du descriptif (statistiques descriptives), soit si on veut expliquer il faut d’abord décrire (statistiques descriptives puis inférentielles).
I. Les méthodes en psychologie : méthodes d’étude et méthodes statistiques.
1. Les méthodes du psychologue :
a. L’observation :
Observation : c’est l’étude d’un phénomène naturel ou culturel sans que l’observateur n’intervienne dans le déroulement de ce phénomène. Pour être valide, l’observation doit être communicable et surtout vérifiable et répétable.
C’est la plus ancienne méthode en psychologie, on a commencé par observer le comportement des individus. Mais d’autres disciplines utilisent l’observation.
Les chercheurs, ayant des difficultés avec l’observation, manque de fiabilité, ont tenté de mettre au point plusieurs méthodes d’observation :
– Observation libre : on observe sans intervenir. S’effectue généralement en milieu naturel. En développement, ça a longtemps été utilisé, dès le XVème et XVIème siècle, mais ce n’était pas fiable. La plupart du temps il s’agissait de médecins qui observaient leurs enfants, leurs observations étaient donc influencées par l’amour filial.
– Questionnaires : toujours sans intervenir, le psychologue reste neutre. Le questionnaire, ou enquête, dirige l’observation. Les enquêtes sont pour un nombre important d’individus. Donc là, on demande à un individu de répondre à un questionnaire, mais les réponses ne sont pas toujours vraies, l’individu répond ce qu’il veut. Il faut donc être prudent avec les questionnaires et avec le type de questions. Ex : on n’aurait pas les mêmes réponses sincères, si on demande « quel marque de dentifrice utilisez-vous ? » et si on demande « êtes-vous pour ou contre la peine de mort ? ».
– Observation directe : observation dans un environnement naturel ou en laboratoire. En laboratoire, un milieu artificiel est construit, et les individus sont placés à l’intérieur, et le psychologue observe sans intervenir. En général, ce type de milieu artificiel force les comportements, mais certaines expériences ont besoin d’un cadre structuré. Ici, en laboratoire, on parle de validité écologique, on essaye de se rapprocher le plus possible de l’environnement dans lequel évoluent les individus, mais ça ne veut pas dire naturel, c’est s’en rapprocher. Néanmoins, il y a toujours un problème avec l’observation, c’est l’observateur. Juste par sa présence on est influencé (ex : effet observateur, devant un observateur une maman va accentuer son rôle pour montrer qu’elle est une bonne mère).
→ Différence entre observation libre et observation directe : dans l’observation libre, en général cela se passe en milieu naturel, et il n’y a pas de démarche scientifique.
– Observation armée : pour éviter l’effet observateur, ce dernier est remplacé par une caméra. Le problème est toujours le même, on sait qu’il y a la caméra donc on modifie le comportement. Le seul intérêt c’est dans l’observation filmée, ce qui donne une preuve, on ne se fie pas qu’à l’observateur.
– Observation ouverte ou fermée :
+ Observation ouverte : aucun aspect du comportement n’est défini au préalable, pas d’hypothèse précise, on observe le comportement en général.
+ Observation fermée : correspond à une hypothèse plus précise et s’appuie sur des grilles d’observation, donc les données sont plus précises. Néanmoins, ces grilles sont trop rigides, non exhaustives, elles ne comprennent que quelques aspects, et si un comportement autre apparaît on ne le note pas, on ne le prend pas en compte.
L’observation reste utilisée, mais comporte de nombreux défauts, et actuellement on considère que pour les minimiser il faut filmer les comportements des individus puis avoir recours à des juges pour regarder l’enregistrement et noter des comportements. S’ils ne sont pas unanimes dans leur observation, on rejette les résultats de l’observation. La méthode des juges renforce la méthode d’observation. Mais on ne le fait pas à l’insu de l’individu, ce n’est donc pas tout à fait fiable.
Quelles statistiques utiliser pour l’observation ?
Les statistiques descriptives, mais on ne fait pas de moyenne. On peut faire des pourcentages, mais cela reste limité.
Les statistiques inférentielles, uniquement si on a des pourcentages (Khi deux), mais c’est non paramétrique.
b. Les méthodes cliniques :
Il y a de l’observation aussi.
On utilise des tests, qui peuvent conduire à faire des statistiques.
Il y a 2 grands types : les tests d’efficience et les tests de personnalité. Certains considèrent une troisième catégorie, les tests psychotechniques, mais on peut les classer dans les tests d’efficience.
Tests d’efficience : comme le WISC IV, NEPS… ce sont des tests étalonnés, pour savoir si on est dans la norme ou pas. Capacité intellectuelle globale, l’état de développement mental, les aptitudes et les connaissances. L’objectif est de déterminer l’aptitude d’un individu face à telle ou telle tâche cognitive ou son « âge mental ».
Tests de personnalité : comme Rorschach, non étalonnés, mais maintenant certains tests le sont. Avec 2 types, soit les tests projectifs soit les questionnaires étalonnés. Interprétés en termes numériques : Explorent l’affectivité, l’intérêt, les motivations et les manières d’être et d’agir. 3 objectifs : Étude du développement affectif et émotionnel, « Classification » de l’individu dans un profil (paranoïa, dépression, etc.), Mettre en évidence la présence ou l’absence de signes pathologiques pour une prise en charge adaptée. → Ils permettent de définir un profil type.
c. La méthode expérimentale :
C’est la plus utilisée en psychologie.
Expérimenter : c’est pour contrôler et faire varier les conditions d’apparition et de déroulement d’un phénomène, de façon à déterminer et mesurer leurs influences. Voir l’effet d’une condition sur un comportement. Donc, il s’agit d’une expérimentation que si on fait varier quelque chose. Expérimenter c’est tester une hypothèse.
Expérience : on utilise des variables et on mesure leurs effets sur le comportement. Variable indépendante (VI) que le chercheur manipule, et variable dépendante (VD) qui dépend de l’individu, c’est ce que l’on mesure, elle doit être mesurable.
Echantillon : groupe d’individus que l’on teste. Notion très importante. Doit donc être représentatif de la population. Pour cela, on utilise soit le tirage au sort, qui est le plus simple (le hasard fait bien les choses) et qui doit être de taille importante, ou soit le calcul des caractéristiques de la population pour avoir les mêmes pourcentages dans notre échantillon (ex : 51% de filles et 49% d’hommes dans la population, on doit avoir le même pourcentage dans l’échantillon).
Hypothèse : provient d’un ensemble de théories ou d’observations, ou des deux. L’hypothèse est le moment le plus délicat de l’expérimentation, si on loupe ça on loupe tout le reste. L’hypothèse doit donc être vérifiable, elle doit être mise en relation avec des faits observables (ex : si on met en relation les conditions de travail et la réussite aux examens). C’est une prédiction qui met en relation une variable et un comportement.
Il y a 3 types d’hypothèses : générale, opérationnelle, statistique. Du général au plus fin :
– Générale : la toute première posée par le chercheur. Non précise. Elle dit qu’elles sont les effets que la future expérience aura sur le comportement. Peut être formulée au présent car c’est du général. Ex : l’alcool influence les résultats universitaires.
– Opérationnelle : toujours formulée au conditionnelle. Rend testable l’hypothèse générale, on opérationnalise les variables utilisées. On doit donc y voir VI et VD. Ex : un taux élevé d’alcoolémie supérieur à 1g devrait provoquer une baisse de la moyenne des notes obtenues aux examens. Ici, le taux d’alcool c’est la VI, et la baisse des notes c’est la VD. On peut aussi formuler l’hypothèse par « Si (VI) alors (VD) ».
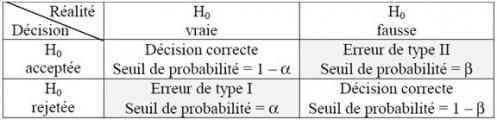
– Statistique : pour vérifier les hypothèses formulées. H0 (hypothèse nulle) pour dire que rien ne se passe, que la VI est sans effet sur la VD, et H1 (hypothèse alternative) pour dire que la VI a un effet sur la VD. Grâce à cela, on accepter l’hypothèse opérationnelle. Permet aussi de voir si on peut généraliser à la population. On rejette H0. Il faut bien spécifier qu’on attend un changement dans l’ensemble de la population. Ex : pour H0 = dans l’ensemble de la population, un taux d’alcoolémie élevé ne provoque pas d’effet sur la note moyenne obtenue aux examens ; pour H1 = dans l’ensemble de la population…c’est l’inverse. Il y a 2 types d’erreurs : rejeter H0 alors qu’il ne faut pas, H0 est vrai ; et inversement ne pas rejeter H0 alors qu’il aurait fallu le faire. Les tests statistiques tiennent compte de ce type d’erreur. Il faut donc savoir quel test statistique approprié choisir pour trancher entre H0 et H1.
– Les hypothèses sont posées avant bien sûr, le début de l’expérience. C’est ce qu’on dit hypothèse à priori. Toutefois, il arrive que le chercheur obtienne des résultats intéressants, et qui ne vont pas dans le sens de ses hypothèses, on en pose d’autres, qu’on appelle hypothèse à posteriori, et qui sont plus délicates à tester puisqu’elles sont posées après. On n’utilise pas les mêmes tests statistiques pour ces hypothèses.
Variables :
– VD (variable dépendante) : aspect du comportement qui doit absolument être mesurable et dépendante, car dépend de l’individu et non du chercheur. C’est une réponse comportementale fournie par l’individu que le chercheur teste. Ex : temps de réaction. On se fiche du temps lui-même, mais on s’intéresse à ce qui se cache derrière. On peut opposer les mesures en temps réel (on-line) et celles non en temps réel (off-line). Une VD doit avoir 4 qualités pour être réplicable :
+ La VD doit être pertinente, doit mettre en évidence l’aspect cognitif qui intéresse.
+ La VD doit être sensible aux facteurs que l’on manipule, elle doit permettre de mettre facilement en évidence des variations. Ex : le temps de réaction se mesure en ms, il faut de la finesse.
+ La VD doit être claire, il faut pouvoir la définir sans aucune ambigüité.
+ Et la VD doit être fiable, doit comporter peu d’erreurs, l’outil de mesure doit être choisi avec soin.
– VI (variable indépendante) : c’est un facteur expérimental, c’est ce que manipule le chercheur. Ca peut être une caractéristique de l’environnement ou du participant. La VI doit prendre plusieurs valeurs/modalités, au moins 2, il faut au moins 2 façons de faire varier quelque chose. Différentes catégories de VI :
+ VI inférente à l’environnement ou au participant :
. A l’environnement = provoquée, car c’est l’expérimentateur qui la provoque. Ex : peindre un mur noir.
. Au participant = invoquée ou étiquette, caractéristique du participant. Ex : le sexe.
→ Attention, il existe des variables participant qui sont provoquée, et des variables environnement qui sont invoquées. Avec les variables provoquées on peut soit partager l’échantillon en 2, soit faire passer 2 fois l’épreuve à tout l’échantillon. Avec ce dernier on contrôle la variabilité interindividuelle. Avec les VI provoquées on a moins de contraintes.
+ VI fixe ou aléatoire (indépendamment des précédentes) et parasites :
. Fixe ou fixée ou systématique : quand seules les modalités qui apparaissent dans l’expérience intéressent le chercheur, simplement les modalités sont fixées une fois pour toute, elles ne vont plus bouger. Si un chercheur réplique l’expérience, il devra utiliser les mêmes modalités.
. Aléatoire : lorsque le chercheur veut généraliser les résultats obtenus à d’autres modalités qu’il n’avait pas prises en comptes, des modalités tirées au sort. A éviter car pénible à vérifier statistiquement.
. Variables parasites : vont influencer le déroulement de l’expérience sans que le chercheur s’en aperçoive. Il s’agit de variables qui ne sont pas contrôlées et qui vont moduler la VD.
– Lorsqu’on met en place une expérience, il faut prendre en compte toutes les variables qui vont intervenir dans l’étude.
+ Les dernières caractéristiques des VI sont :
. Des facteurs d’intérêt : on peut aussi les appeler variable principale ou facteur principal. VI pour lesquelles l’expérience a été construite, permettent de mettre en évidence l’effet des facteurs sur la VD.
. Des facteurs de contrôle : aussi appelée facteur/variable secondaire. VI permettant d’améliorer la validité ou l’efficacité de l’étude pour prendre en compte des sources potentielles de variations. Ces sources ne vont pas forcement intéresser les chercheurs. Ce sont des VI qu’on va soupçonner d’affecter la VD, mais de façon secondaire. On peut choisir d’éliminer ces variables, de ne pas tenir compte de ces facteurs, de trois manières :
– Constance : on maintient constantes les modalités de la VI secondaire.
– Contre-balancement ou des rotations : on combine toutes les modalités de la VI par des rotations. Surtout utilisée pour éliminer les effets de rang (ordre de passation). Méthode relativement couteuse puisqu’elle peut augmenter considérablement les effectifs, mais c’est la plus efficace.
– Randomisation : intervient quand le contre-balancement est trop lourd. On tire au sort l’ordre de passation pour chaque participant. On fait confiance au hasard. Très utilisée, même si la plus efficace reste le contre-balancement complet.
. Dans l’absolu, les facteurs secondaires qui pourraient influencer la VD, doivent être pris en compte dans les analyses statistiques de l’étude. Les variations que l’on va observer viendront de l’individu ou de l’environnement.
+ L’avantage principal de l’expérimentation c’est le contrôle de toutes les variables. Dans le cas idéal, on va essayer de contrôler tous les facteurs sauf ceux qu’on souhaite étudier : il y a une variation des facteurs externes, en maintenant constants tous les facteurs sauf ceux que l’on veut observer. Les différences qu’on observe dans les résultats seront du aux variations dans l’environnement ou de l’individu choisis par l’expérimentateur. Les changements que l’on observe au niveau de la VI sont la cause que l’on obtient sur la VD.
Relations entre participants et facteurs expérimentaux :
– Modèle expérimental : il faut tout d’abord connaitre les caractéristiques des participants et savoir comment ils vont être influencés par les modalités de la VI. Cela implique le choix d’un plan qui va s’adapter au contrôle expérimental. Donc dès le début de la recherche on va devoir formuler un modèle dans le but de limiter les variables à contrôler :
+ Modèle DANS les participants (intraparticipant/à mesure répété) : les participants passent toutes les modalités de la VI. L’avantage est qu’on peut comparer les participants à eux-mêmes. On peut voir comment ils se comportent dans les différentes modalités de la variable. Ce plan est plus économique au niveau des sujets, comme les participants voient les deux modalités, on n’a besoin que d’un groupe expérimental.
+ Modèle ENTRE les participants (interparticipant/mesure participante) : ils ne voient qu’une seule modalité de la VI. 2 groupes de participants différents. Ce modèle est considéré comme plus rigoureux, plus conservateur parce que le traitement d’une modalité d’une VI ne peut pas influencer l’autre modalité. Les résultats ne seront donc liés qu’à une seule modalité de la VI. L’avantage de ce modèle, c’est qu’on va pouvoir comparer le participant à lui-même (voir comment il se comporte dans les modalités 1 et 2). Besoin d’un seul groupe expérimental.
– Pour choisir, il faut regarder les modalités de ses VI et particulièrement des VI provoquées, soit les participants passent toutes les modalités de la VI soit qu’une partie. Dans le cas des VI invoquées, le chercheur n’aura pas le choix puisqu’il s’agit des caractéristiques propres à l’individu. L’étude dépendra donc de ces caractéristiques.
– Quand il y a plusieurs VI on parle de plan factoriel, il permet d’utiliser des statistiques d’analyse de variance et analyser les effets respectifs de chaque VI sur chaque VD ainsi que les effets d’interaction entre les différentes VI. On va pouvoir analyser les différentes interactions qu’entretiennent les VI.
Groupe :
– Groupes appareillés : les participants voient toutes les modalités des VI, ils passent toutes les conditions expérimentales. On va croiser les participants à toutes les modalités de toutes les VI. Le participant voit toutes les VI et toutes les modalités. On n’a pas besoin de s’intéresser à l’équivalence des groupes.
– Groupes indépendants et équivalents : on va avoir plusieurs groupes de participants, ils ne voient qu’une partie de l’expérience seulement. On aura autant de groupes expérimentaux que de modalités de la VI (ex : 4 groupes expérimentaux pour 4 modalités). Il y aura plus de participants et on aura un problème de l’équivalence des groupes. Est-ce que nos participants ont les mêmes caractéristiques entre les groupes ? (ex : il faut comparer des personnes du même âge, le genre, le niveau socioculturel…pour savoir si l’effet est bien dû à la VI et pas à des parasites).
– Groupe contrôle et condition contrôle : le groupe contrôle se réfère à des participants, les modalités de la VI qui intéresse le chercheur n’interviennent pas. Les performances de ce groupe vont servir de référence. Cela nous permettra de faire une comparaison entre le groupe contrôle et les autres groupes expérimentaux pour voir si les effets de la VI ont un influence sur les groupes expérimentaux par rapport au groupe contrôle. Il y aura toujours au moins deux groupes de participants. Un groupe expérimental et un groupe contrôle. Le groupe expérimental permet aussi de mesurer la condition contrôle. Elle permet d’obtenir une référence et où les facteurs principaux ne vont pas intervenir. Ils vont avoir des caractéristiques communes : dès le départ on va indiquer des caractéristiques qui nous intéressent (ex : enfants de CM2), ceci va conduire à l’appariement. Une caractéristiques commune et le reste diffère.
2. Méthodes et tests statistiques :
a. Méthodes descriptives et méthodes explicatives :
Le choix des statistiques et des types d’analyses que l’on va utiliser va déterminer la manière d’étudier les données et de les interpréter.
Les méthodes descriptives : on va prendre en compte soit une partie des données, soit l’ensemble des données mais en les considérant sur le même plan. Ce sont des méthodes qui permettent de décrire de manière synthétique les données, de les résumer. Va nous permettre d’avoir une vue d’ensemble de nos résultats. Une fois les données recueillies c’est le point de départ, les statistiques descriptives sont les premières qu’on applique aux données. Elle comprend :
– Le calcul des indices de tendance centrale : le mode, la moyenne et la médiane. Cela permet d’obtenir des graphiques qui permettent d’avoir une vue d’ensemble sur les résultats.
– Le calcul des indices de dispersion : la variance et l’écart-type. Ont pour objectif de réduire l’information contenue dans la distribution des notes. On va obtenir un résumé numérique et un résumé graphique des performances.
La méthode explicative : c’est pour aller plus loin dans l’interprétation de nos données une fois la méthode descriptive terminée. On appelle ces méthodes inférentielles ou inductives. On va utiliser ces méthodes pour 2 catégories de variables :
– Variables à expliquer : dont on cherche à comprendre et analyser les variations par des variables dites explicatives. Ce type d’analyse va nous permettre de généraliser nos résultats. On va passer par des tests inférentiels pour nous permettre de généraliser à l’ensemble de la population les résultats de notre échantillon. Il s’agit d’inférer les résultats de la population à partir de ceux de notre échantillon. On utilisera les tests statistiques, ils vont nous permettre de tester empiriquement nos prédictions ou nos hypothèses par rapport aux données obtenues. Les variables à expliquer sont les variables dépendantes.
– Variables explicatives : ce sont les variables indépendantes. Cela va nous permettre de démontrer statistiquement que des variables influencent d’autres variables. On va tester notre hypothèse alternative contre l’hypothèse nulle.
On va réaliser des calculs et on va obtenir une valeur que l’on va comparer à un critère de décision et c’est cette valeur qui va nous permettre de dire si l’hypothèse nulle peut ou pas être rejetée.
Il est toujours plus pertinent d’aborder le problème avec une méthodologie structurée, 2 étapes :
– Mettre en évidence des groupes d’individus homogènes, des liaisons entre les variables. Les méthodes descriptives permettent d’avoir une vision globale et synthétique du problème traité grâce à des graphiques, des tableaux récapitulatifs, quelques calculs élémentaires et quelques indices statistiques descriptifs.
– Expliquer en validant statistiquement les résultats et en les généralisant à la population participante, en clarifiant les relations entre les variables.
b. Que choisir ?
Le choix de la ou les méthodes appropriées dépend donc de bien des facteurs tels que le type de variables et leur codage, va dépendre de l’objectif. Décrire ou expliquer, dépendra de l’échantillon des sujets, du type de données recueillies…
C’est toujours mieux de débuter par une description des données qu’on peut étayer par une représentation graphique qu’on peut considérer comme une étape essentielle. La représentation graphique est une démarche d’investigation à part entière et pas uniquement comme une simple représentation des résultats.
On a déjà une approximation de la répartition des données. Très utile pour étayer ou conforter les calculs. On va utiliser des statistiques qui vont dépendre de la nature des variables sur lesquelles on travaille.
Exercice 1 :
Dans une recherche sur la mémorisation, des participants doivent apprendre une liste, ils sont soumis à l’une de ces deux techniques d’apprentissage. Le 1er groupe doit apprendre par cœur, le second doit regrouper les items par catégorie.
Trouver les VI / Plan d’expérimentation / Hypothèses :
– VI = Technique d’apprentissage ; Modalités par cœur OU par regroupement.
– VI : provoquée fixe.
– Plan inter-participants (Chaque individu ne voit qu’une seule condition expérimentale) ; S <T2 > Plan emboîté.
– Hypothèse nulle H0 : « Dans l’ensemble de la population, les performances du groupe par cœur devraient être identiques à celles du groupe avec consignes d’apprentissage. »
– Hypothèse alternative H1 : « Dans l’ensemble de la population, le groupe avec consigne d’apprentissage devrait rappeler significativement plus de mots que le groupe par cœur. »
Exercice 2 :
Un chercheur en psychologie du développement s’intéresse à l’effet de la complexité des phrases sur leur vitesse de traitement. Il pense que les textes comportant des phrases simples devraient être lus plus rapidement que les textes avec des phrases complexes. Il propose deux versions d’un même texte aux participants. Une version simple et une version complexe. Des filles et des garçons âgés de 10-12-14 et 16 ans lisent l’un des deux textes.
Trouver les VI / VD / Plan / Hypothèses :
– VI = Texte (2) ; Age (4) ; Genre (2).
– VI : provoquée, fixe inter-participants.
– VD = Vitesse de lecture.
– Plan expérimental : Les participants ne voient qu’une seule modalité de chaque VI. S <T2 x A4 x G2>.
– 6 hypothèses : Pour chaque VI, il faut une hypothèse nulle et une hypothèse statistique.
II. Pour commencer : statistiques descriptives.
1. Introduction : le cheminement d’une recherche :
La mise en œuvre d’une méthode d’analyse des données est fonction de l’objectif initial et du type de données recueillies.
Quelque soit la méthode statistique choisie, le chercheur suit un plan de travail classique :
1. Définir le ou les objectifs de l’étude et poser ou donner toutes les hypothèses de travail.
2. Choisir les variables fonction de ses hypothèses attestées et les participants représentatifs de la population que l’on veut étudier.
3. Le recueil des données : réaliser une expérience, observation ou enquête. De ce recueil va dépendre la qualité des résultats.
4. Mettre en forme les données, on fait un tableau récapitulatif qui permet une vision globale des résultats. Il faut le plus souvent coder les données. On va pouvoir éliminer les données mal récoltées et on peut les enlever. Nettoyage des données. On doit retirer les données aberrantes qui pourraient fausser les statistiques.
5. Choisir une technique d’analyse appropriée au traitement des données. On peut commencer par faire une analyse de variances et on peut faire des statistiques descriptives, graphiques.
6. Exécution des analyses : avec un logiciel de traitement statistique. Bien maîtriser les données pour faire des analyses satisfaisantes.
7. Commenter les résultats obtenus : décrire par des commentaires verbaux des résultats qu’on a obtenus grâce à l’analyse statistique. Commentaires guidés par nos objectifs ou l’hypothèse de départ.
8. Interpréter et discuter les résultats puis conclure. L’étape la plus difficile puisqu’il faut faire un va et vient entre les résultats obtenus et les hypothèses formulées au départ. On va déterminer si les hypothèses sont validées et on va tenter d’expliquer pourquoi.
Pour résumer cette démarche, il est essentiel qu’il y ait un accord entre le recueil des données, l’analyse et l’interprétation des résultats.
2. Les différents types de variables et de mesures :
Pour définir la nature des données recueillies, le terme d’échelle est généralement utilisé. Il permet de préciser la nature des variables ou des mesures effectuées.
Il existe 4 types d’échelles fréquemment employées dont 3 particulièrement utilisées en psychologie. Le choix du type d’échelle conditionne l’analyse des données (nominale, ordinale, d’intervalle, et de rapport). Ce classement définit la précision d’informations sur le phénomène donnée par les différentes échelles.
a. Les échelles de mesure :
4 types d’échelles :
– Les échelles nominales : il n’existe pas de critères pour ordonner les valeurs, qui sont qualitatives. Elles sont rangées dans des classes disjointes, chaque valeur n’appartient qu’à une seule classe et l’ensemble des classes constituent l’échelle nominale. Cette échelle permet d’identifier la catégorie à laquelle appartient l’observation ou la valeur en fonction d’une caractéristique définie a priori. Ce ne sont pas des mesures. La seule relation entre les éléments d’une même classe est une relation d’équivalences. Les valeurs attribuées aux variables jouent simplement le rôle d’étiquettes. Ce qui permet d’identifier les individus pour les items utilisés. Ces échelles caractérisent les variables descriptives sur lesquelles elles portent. Lorsqu’il y a deux classes, on parle de variables binaires (codées 0 et 1) ou dichotomiques. Bien entendu ces variables peuvent avoir plusieurs classes, appelées polychotomiques. Toutes les catégories de ce type d’échelle sont indépendantes. Ex : échelle fondée sur le sexe a 2 classes, on code 1=masculin et 2=féminin valeur nominale binaire. Ces chiffres de codage n’ont aucune valeur statistique. Absence de hiérarchie entre les catégories. Toutes les catégories sont considérées comme équivalentes. On fait peu de traitements statistiques, à part une répartition des données (mode, pourcentage…).
– Les échelles ordinales : sont aussi qualitatives et ont donc les mêmes propriétés que les échelles nominales. Il existe un ordre de progression. Ex : rang obtenu par des individus après un examen ou une épreuve sportive. Aucune information sur l’intervalle entre les rangs ni la valeur de ces intervalles. Elles vont permettre de classer les individus les uns par rapport aux autres. Une variable continue peut être transformée en variable ordinale en faisant des catégories d’âge par exemple. Les échelles d’attitude et d’opinion sont les plus utilisées : échelle de Lickert (du moins d’accord au plus d’accord). Les opérations statistiques utilisées sont les mêmes que pour les échelles nominales sauf qu’ici on peut en plus déterminer la médiane (la valeur du milieu) et calculer des corrélations par rang. On ne calculera pas la moyenne car cela n’est pas pertinent.

– Les échelles d’intervalles : elles possèdent les mêmes propriétés que les échelles ordinales mais supposent en plus l’existence d’intervalles mesurables de distance entre les réponses. Il s’agit de variables quantitatives ou numériques et le fait de mesurer va impliquer d’introduire une distance stable entre les différentes mesures ou observations. Ces échelles vont permettre beaucoup plus de traitements statistiques et mathématiques que les autres échelles car elles possèdent des unités de mesure constantes avec une particularité : le point 0 est fixé arbitrairement il n’a pas de signification. Ex : échelle de température, mesure du QI. Variables dont les modalités peuvent être représentées par des nombres qui peuvent être soit entiers (variable discontinue ou discrète comme par exemple le nombre d’enfants dans une famille ou le nombre de mots rappelés à un test de mémoire), soit ils peuvent être réels et dans ce cas là on parle de variables continues comme par exemple le temps de réaction à un stimulus. Ces échelles permettent d’inférer des différences entre des éléments mesurés. Tous les calculs sont possibles. On travaille surtout sur ces échelles en psychologie.
– Les échelles proportionnelles ou échelle de rapport : on les utilise très rarement en psychologie. Cas particulier d’échelle d’intervalles dans lesquelles un statut particulier est donné à la valeur nulle le 0 qui est cette fois unique (poids, taille, chiffre d’affaires, distance). Le 0 correspond à une absence totale de phénomène (ex : un QI de 0 c’est impossible).
b. La nature des variables :
2 types de variables :
– Les variables métriques ou quantitatives : ce sont des variables qui prennent des valeurs numériques (salaire, âge, etc.). Elles peuvent être discrètes ou discontinues ou continue. Pas de valeur intermédiaire. On peut effectuer toutes les opérations statistiques et mathématiques.
– Les variables non-métriques : elles prennent des modalités non numériques comme le genre, la CSP,… Les opérations possibles sont les effectifs et les pourcentages.
c. Transformer la nature des variables :
Au cours d’une recherche, il peut être intéressant de comparer plusieurs variables. Pour cela il faut qu’elles aient la même nature.
Transformation de variables métriques en non métriques : il faut constituer des classes d’amplitude égale ou l’intervalle sera identique (ex : de 10 en 10) ou constituer des classes d’effectifs égaux (méthode préférée). Les classes d’effectifs égaux ne sont pas affectées par la subjectivité de l’expérimentateur ou de l’enquêteur. Le découpage en classes est ici très rigoureux et ne nécessite pas de questionnements. La bonne moyenne de classes étant ni trop ni trop peu. S’il y a trop de classes, les effectifs seront très faibles et nos résultats n’auront plus vraiment de sens. Ex : On peut classer les résultats en 5 classes : très bon, bon, moyen, mauvais, très mauvais. On a des mots, on a remplacé les notes brutes par une appartenance à une classe. Cette transformation du métrique en non métrique conduit parfois à perdre de l’information car on passe à des regroupements moins précis, on ne sait plus qui a eu combien mais ça sert pour simplifier les analyses.
Transformation de variables non métriques en métriques : on va remplacer chaque item par un chiffre. La hiérarchie des items doit avoir un sens (ex : petit=1, moyen=2, grand=3). Les distances entre les items doivent être égales (ex : 1, 2, 3). Une fois qu’on connait la nature des variables il est possible de procéder au tri et au rangement des données à l’aide de graphiques et de tableaux.